Feed-Forward 3D Models
本文梳理了前馈 3D 重建模型(Feed-Forward 3D Models)从相机定位到大规模场景恢复的技术演进脉络。从早期的端到端位姿回归(PoseNet),到基于 ViT 和稠密预测的几何重建标杆(DUSt3R 及其演进版 MASt3R),再到完全依靠 data-driven 的 VGGT,前馈模型正逐步摆脱对传统优化对齐的依赖。
前馈重建模型发展历程
PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization
- 利用卷积神经网络 GoogleNet 来实时地进行相机重定位
- 端到端回归出相机的6自由度位姿
- 实现亚米级的定位精度,推理速度达到每秒数十帧
DUSt3R
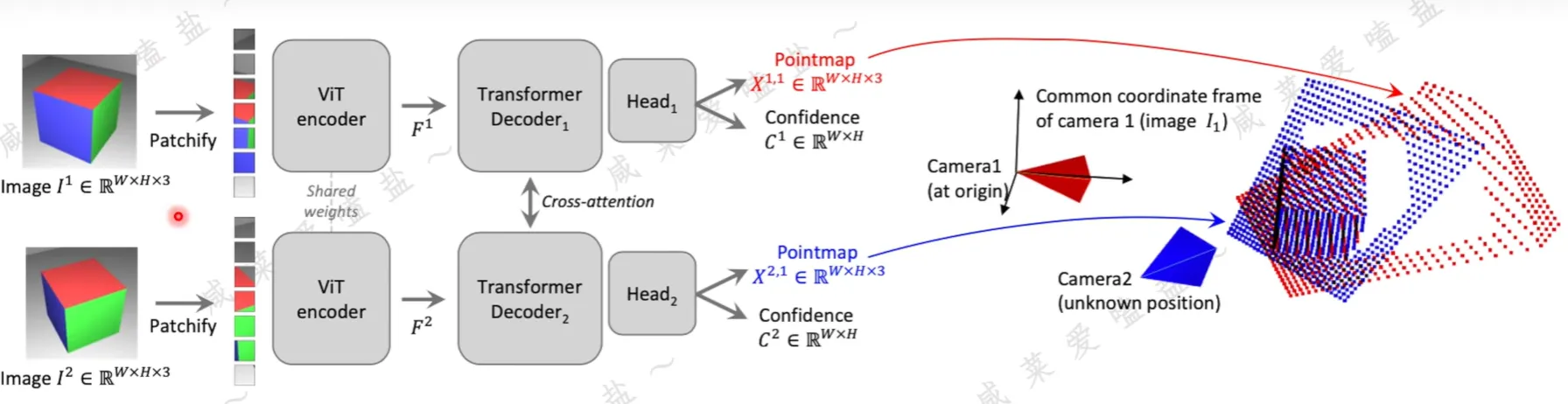
- ViT 编码得到两张图像的特征
- 利用 cross attention 来融合两帧的信息
- 用 DPT(Dense Prediction Transformer) head 来进行稠密预测
- 损失函数:
- 空间点距离损失:$l_{regr}(v, i) = || \frac{1}{z}X_i^{v,1}-\frac{1}{\overline{z}}X_i^{v,1}||$
- 融合置信度的最终损失函数:$L_{conf} = \sum_{v}\sum_{i} C_i^{v,1}l_{regr}(v,i)-\alpha log C_i^{v,1}$
MASt3R-matching
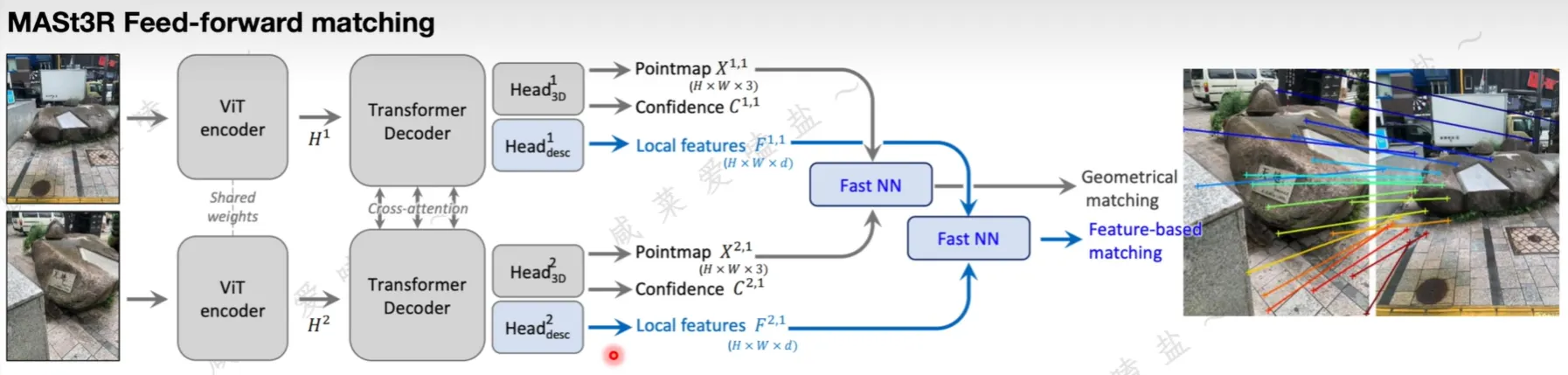
- 在 DUSt3R 的基础上,增加了有关特征匹配的 head
- 损失函数
- 调整 DUSt3R 的损失函数,取消了不同的深度正则化项,直接用深度真值的平均值
- 用于匹配的 infoNCE 损失(希望每个像素点最多和另一张图中的一个像素点匹配)
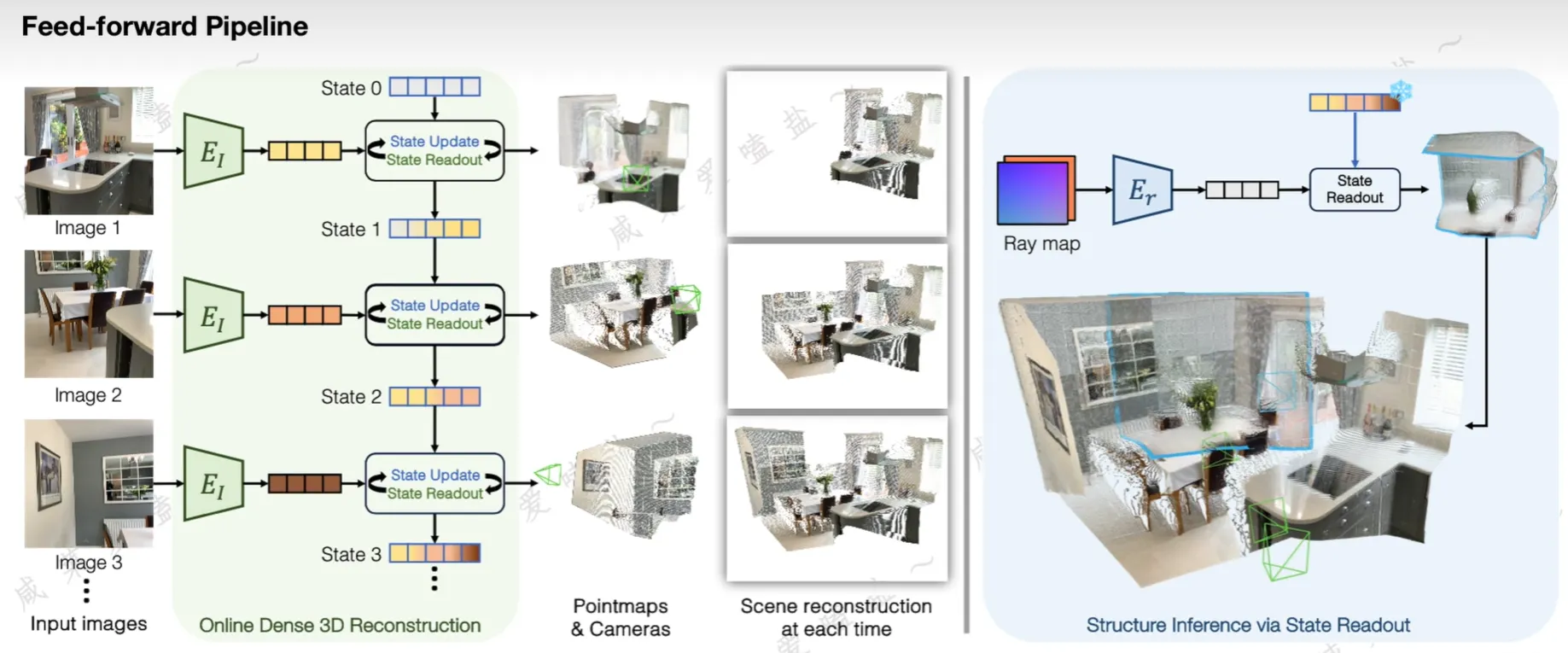
Spann3R
预测每幅图像在全局坐标系下的点云图,从而消除了基于优化的全局对齐的需求
按照键值对的形式组织空间记忆池,在单次推理的过程中:
- 根据前一帧产生的 query feature,查询记忆池中相关性比较高的特征
- 将其与当前帧的图像特征一起送入 Target & Reference Decoder
- 用 DPT head 输出当前图像对应的点云与置信度,以及新的 Q , K , V
CUT3R
Fast3R
解决了成对图像输入的问题
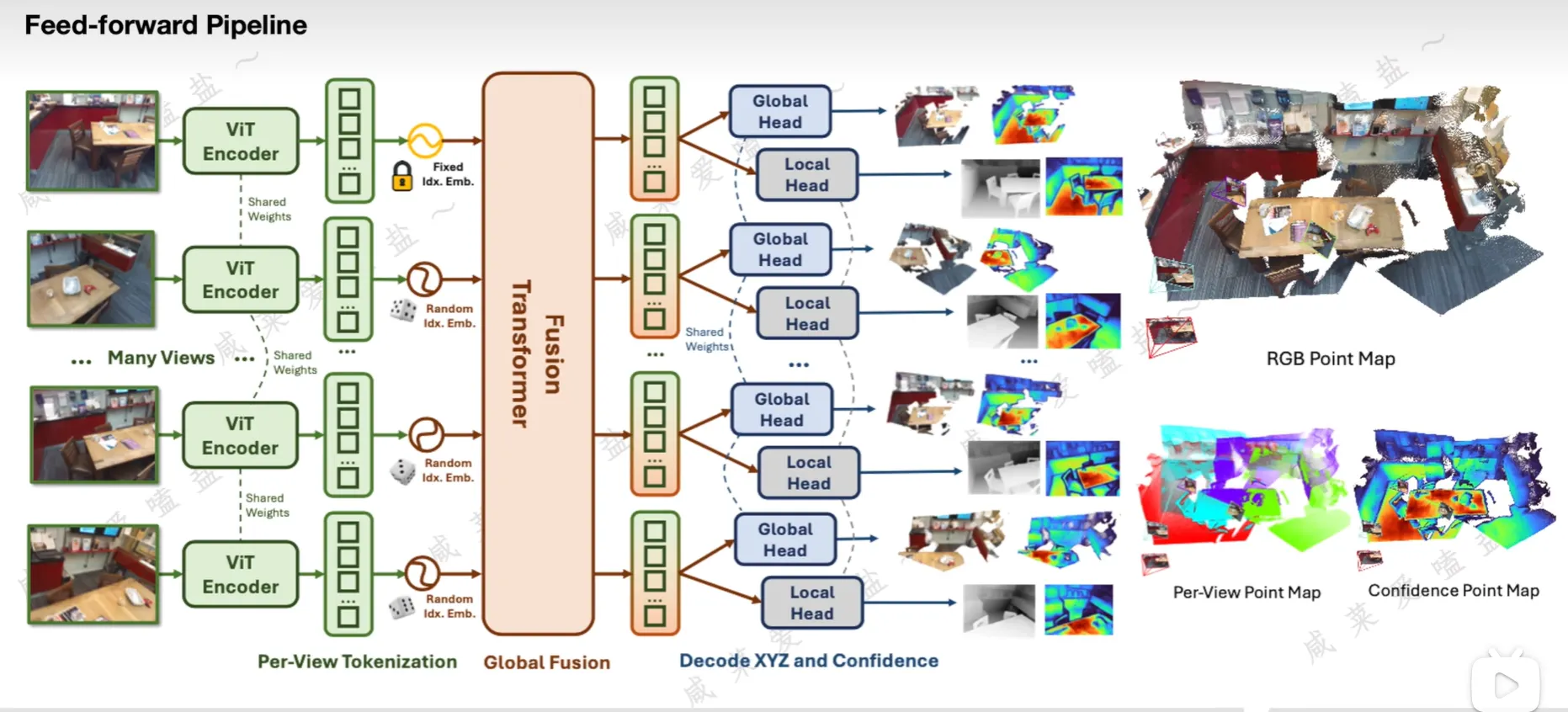
VGGT
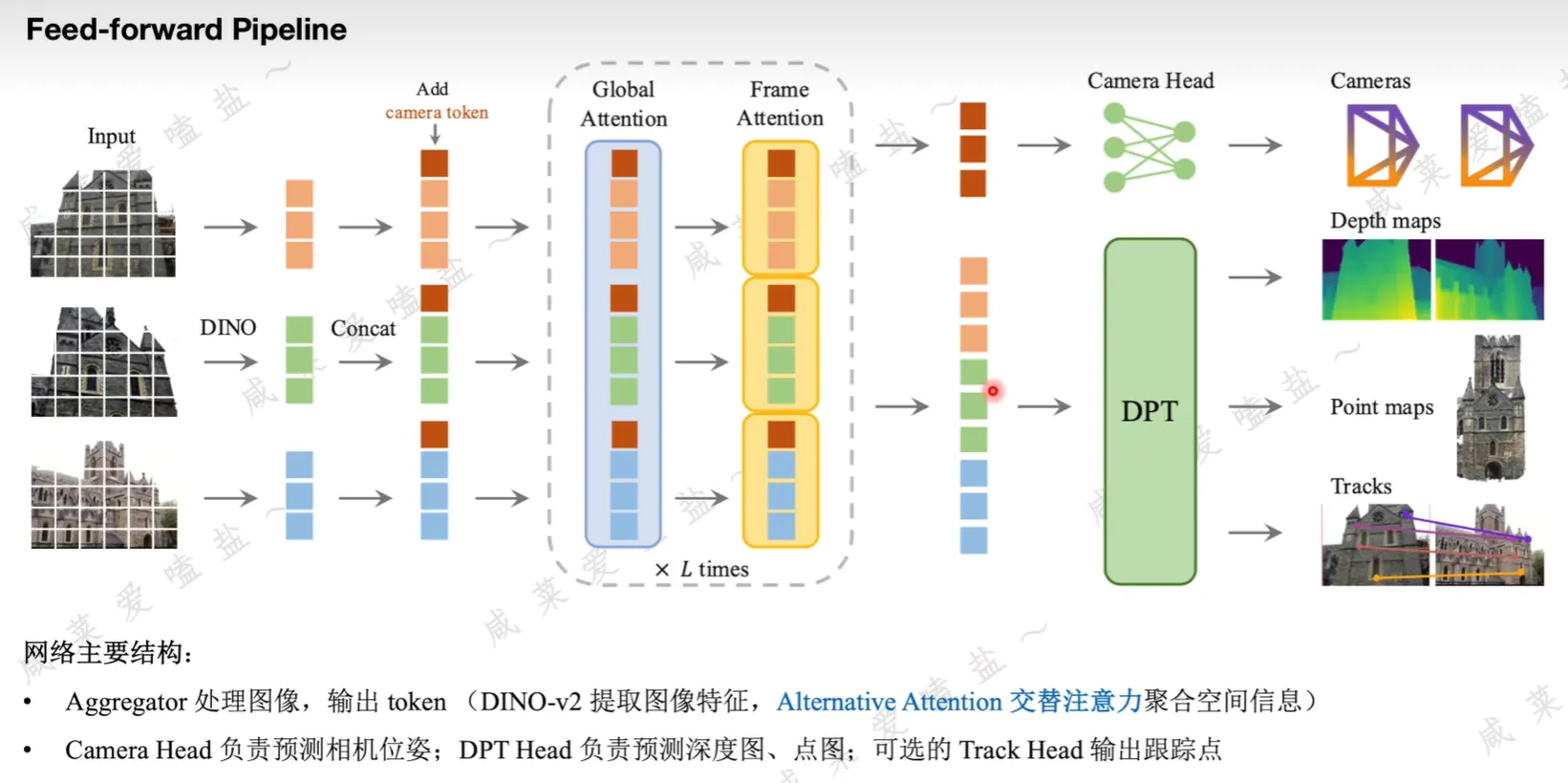
关于 Alternative Attention:通过改变batch维度出现的位置来切换
- frame attention:对每帧内的特征进行关联提取,不同帧的 token 出现在不同的 batch
- global attention:对所有帧的特征进行关联提取,不同帧的 token 出现在同一个 batch
- frame attention 和 global attention 都是 self-attention,整个架构不包含任何 cross-attention,且两者网络参数完全一样
VGGT变体及相关应用
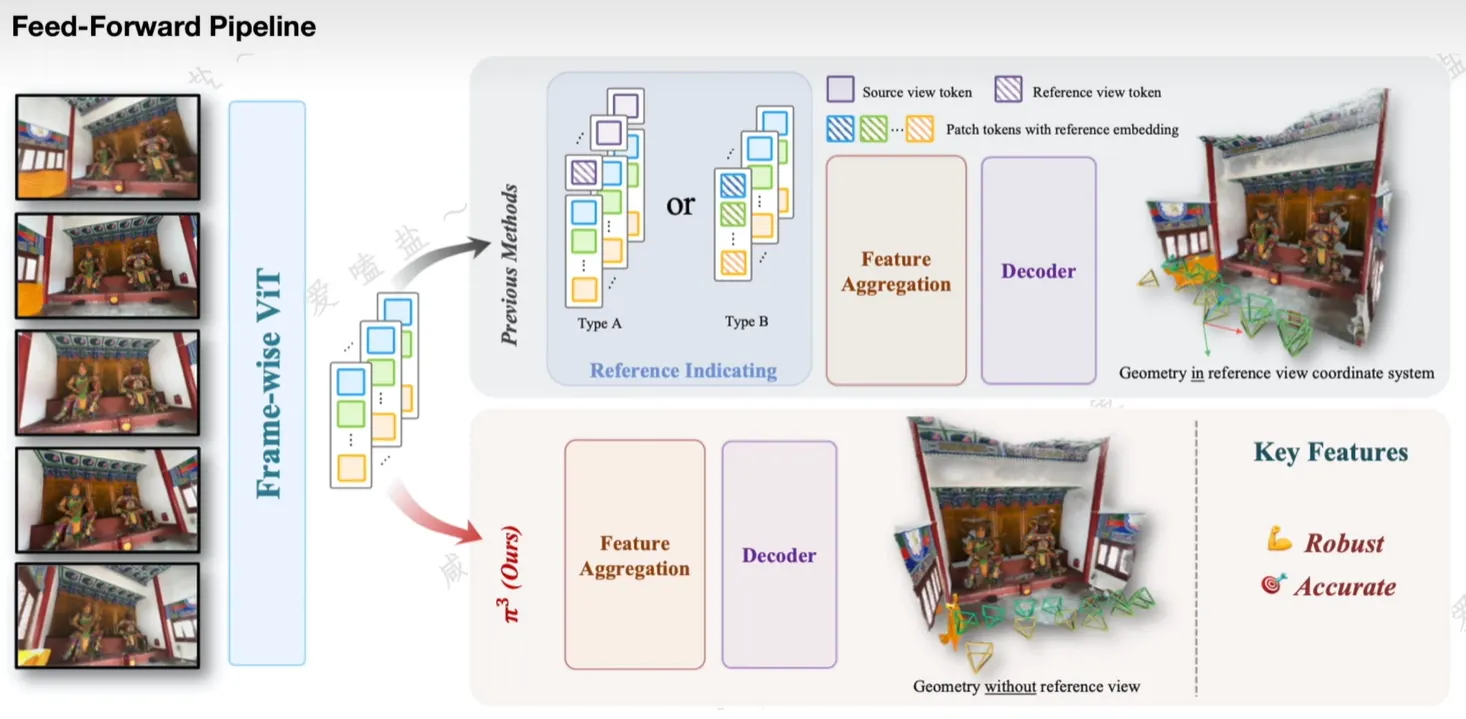
$\pi^3$:Permutation-Equivariant Visual Geometry Learning
- 不依赖于任意参考帧(即不以第一帧作为坐标系)
- Permutation-Equivariant 置换等效性:输出序列与输入顺序一一对应,可任意重排输入序列
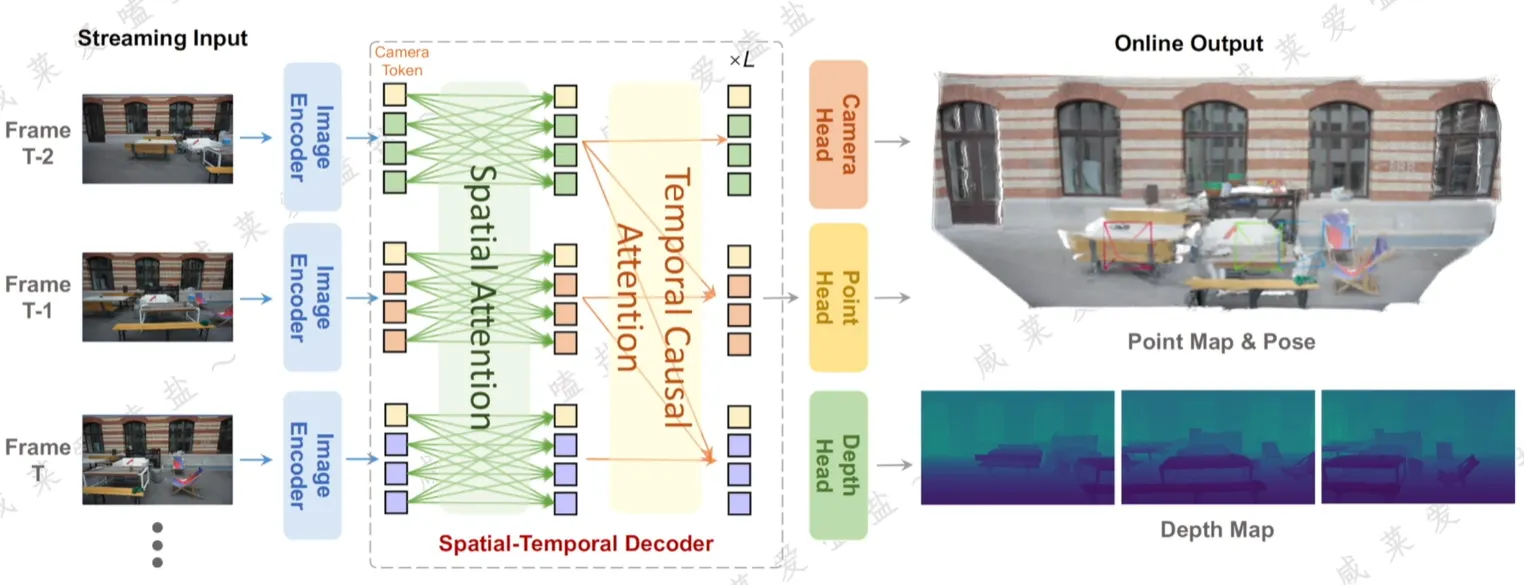
StreamVGGT
针对连续帧视频输入,提出基于“因果注意力”机制的前馈模型,会将历史键对值缓存为隐式记忆token
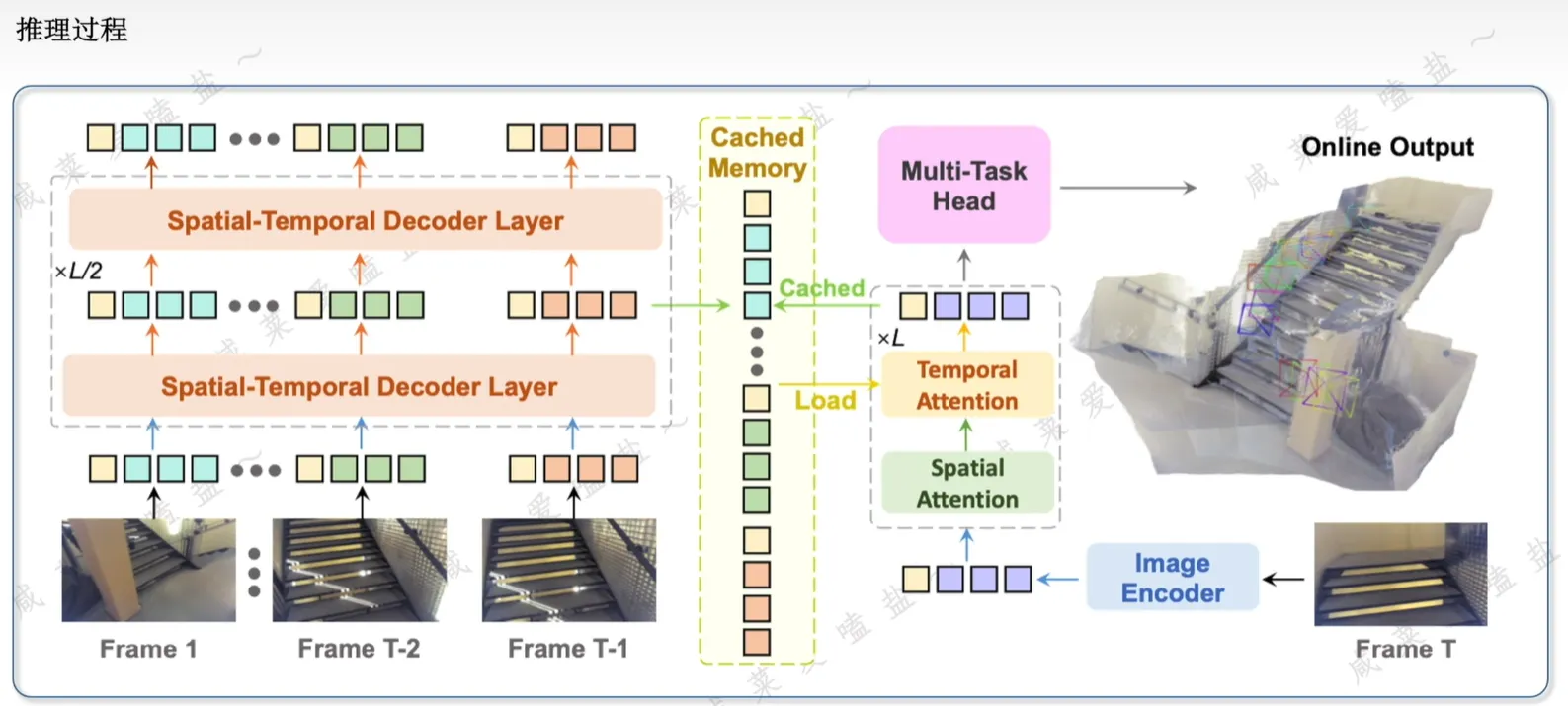
但牺牲的是部分性能(略低于VGGT)
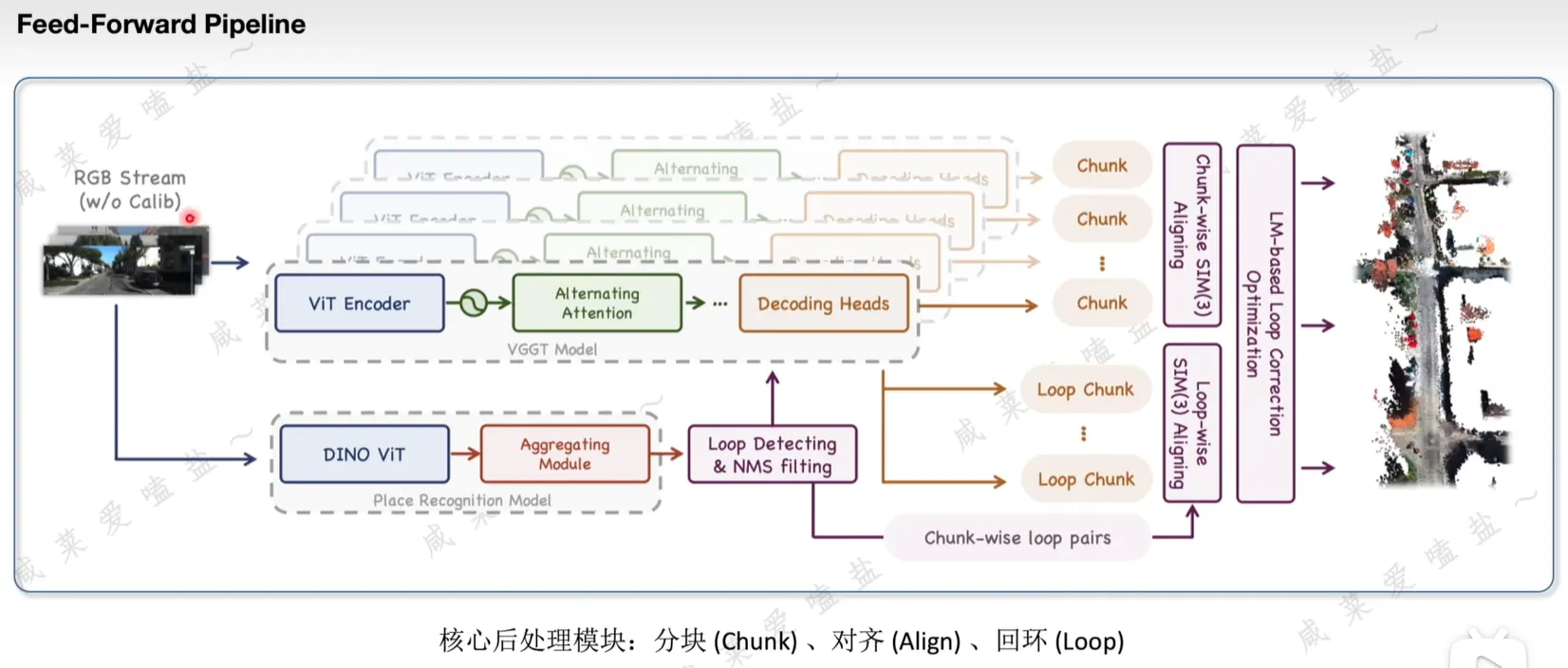
VGGT-Long
此前的方法在小规模场景中表现出色,但当面对长达数公里的视频序列时,这些模型往往会因为显存溢出而崩溃,或者因为误差的不断累计而产生严重漂移